基于VPP+DPDK开源框架开发UPF
DPDK
DPDK是什么
DPDK全称为Date plane development kit,是一个用来进行包数据处理加速的软件库。
为什么DPDK
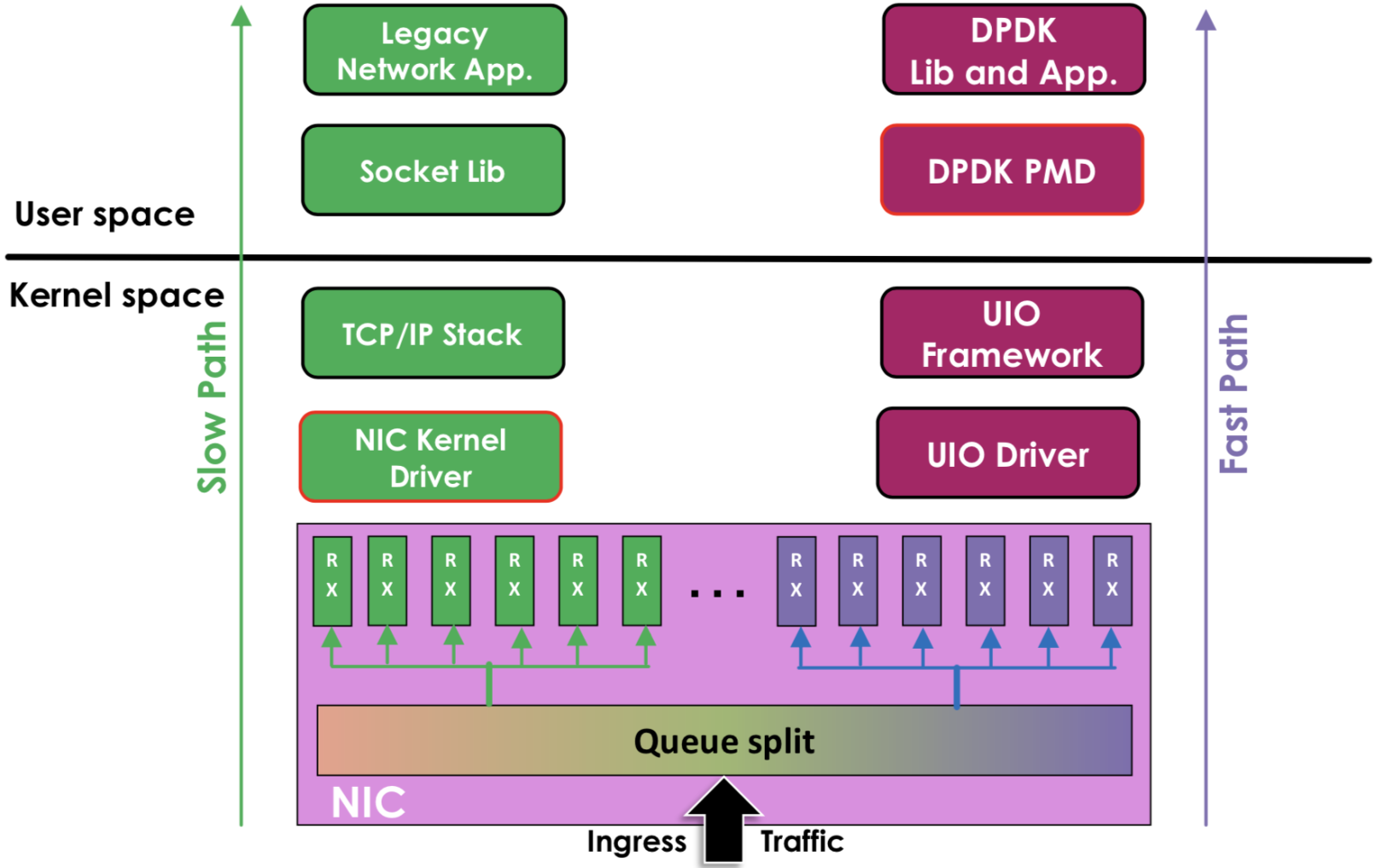
传统 Linux 内核网络数据流程:
硬件中断--->取包分发至内核线程--->软件中断--->内核线程在协议栈中处理包--->处理完毕通知用户层
用户层收包-->网络层--->逻辑层--->业务层
基于传统 OS 内核的数据处理的弊端:
中断处理。当网络中大量数据包到来时,会产生频繁的硬件中断请求,这些硬件中断可以打断之前较低优先级的软中断或者系统调用的执行过程,如果这种打断频繁的话,将会产生较高的性能开销。
内存拷贝。正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%。
上下文切换。频繁到达的硬件中断和软中断都可能随时抢占系统调用的运行,这会产生大量的上下文切换开销。另外,在基于多线程的服务器设计框架中,线程间的调度也会产生频繁的上下文切换开销,同样,锁竞争的耗能也是一个非常严重的问题。
局部性失效。如今主流的处理器都是多个核心的,这意味着一个数据包的处理可能跨多个 CPU 核心,比如一个数据包可能中断在 cpu0,内核态处理在 cpu1,用户态处理在 cpu2,这样跨多个核心,容易造成 CPU 缓存失效,造成局部性失效。如果是 NUMA 架构,更会造成跨 NUMA 访问内存,性能受到很大影响。
内存管理。传统服务器内存页为 4K,为了提高内存的访问速度,避免 cache miss,可以增加 cache 中映射表的条目,但这又会影响 CPU 的检索效率。
如何改进:
控制层和数据层分离。将数据包处理、内存管理、处理器调度等任务转移到用户空间去完成,而内核仅仅负责部分控制指令的处理。这样就不存在上述所说的系统中断、上下文切换、系统调用、系统调度等等问题。
使用多核编程技术代替多线程技术,并设置 CPU 的亲和性,将线程和 CPU 核进行一比一绑定,减少彼此之间调度切换。
针对 NUMA 系统,尽量使 CPU 核使用所在 NUMA 节点的内存,避免跨内存访问。
使用大页内存代替普通的内存,减少 cache-miss。
采用无锁技术解决资源竞争问题。
经很多前辈先驱的研究,目前业内已经出现了很多优秀的集成了上述技术方案的高性能网络数据处理框架,如 6wind、windriver、netmap、dpdk 等,其中,Intel 的 dpdk 在众多方案脱颖而出,一骑绝尘。
DPDK网络数据流程:
硬件中断--->放弃中断流程
用户层通过设备映射取包--->进入用户层协议栈--->逻辑层--->业务层
DPDK的特点:
轮询:在包处理时避免中断上下文切换的开销,
用户态驱动:规避不必要的内存拷贝和系统调用,便于快速迭代优化
亲和性与独占:特定任务可以被指定只在某个核上工作,避免线程在不同核间频繁切换,保证更多的cache命中
降低访存开销:利用内存大页HUGEPAGE降低TLB miss,利用内存多通道交错访问提高内存访问有效带宽
软件调优:cache行对齐,预取数据,多元数据批量操作
DPDK参考
https://www.cnblogs.com/qcloud1001/p/9585724.html
VPP
VPP简介
VPP全称Vector Packet Processing,是Cisco2002年开发的商用代码。 2016年2月11号,Linux基金会创建FD.io项目。Cisco将VPP代码的开源版本加入该项目,目前已成为该项目的核心。 目前各大厂商包括AT&T,Comcast,中兴,华为,博科,思科,爱立信,Metaswitch,英特尔,Cavium,红帽和Inocybe均在此投入大量的资源。
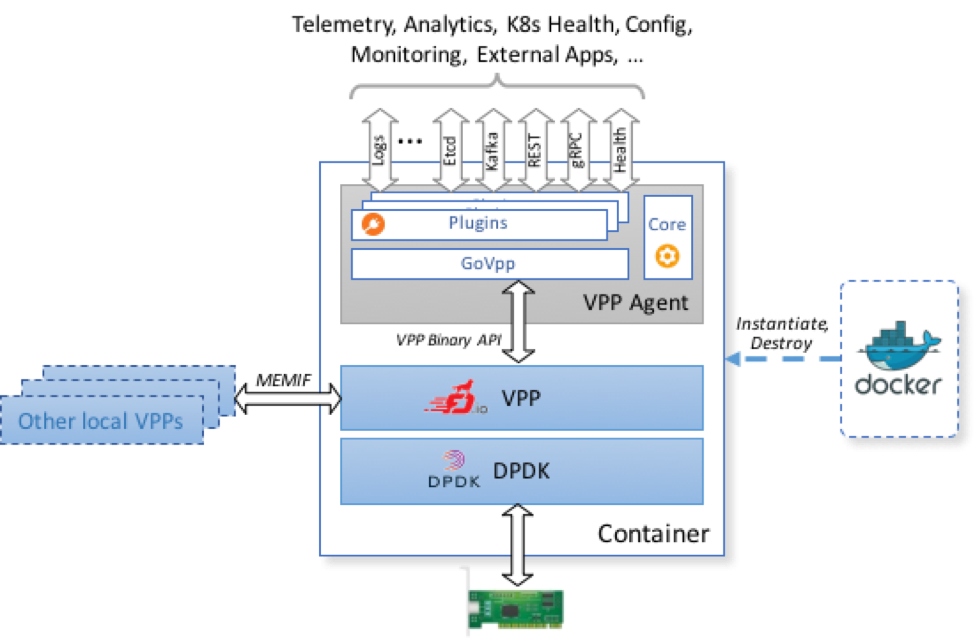
VPP运行于用户空间,支持多种收包方式,常用的是DPDK。 VPP主要有两个功能:框架可扩展;成熟的交换/路由功能。
VPP平台可以用于构建任何类型的数据包处理应用。比如负载均衡、防火墙、IDS、主机栈。也可以是一个组合,比如给负载均衡添加一个vSwitch。
VPP官网: https://fd.io/
项目地址:
GO API地址:
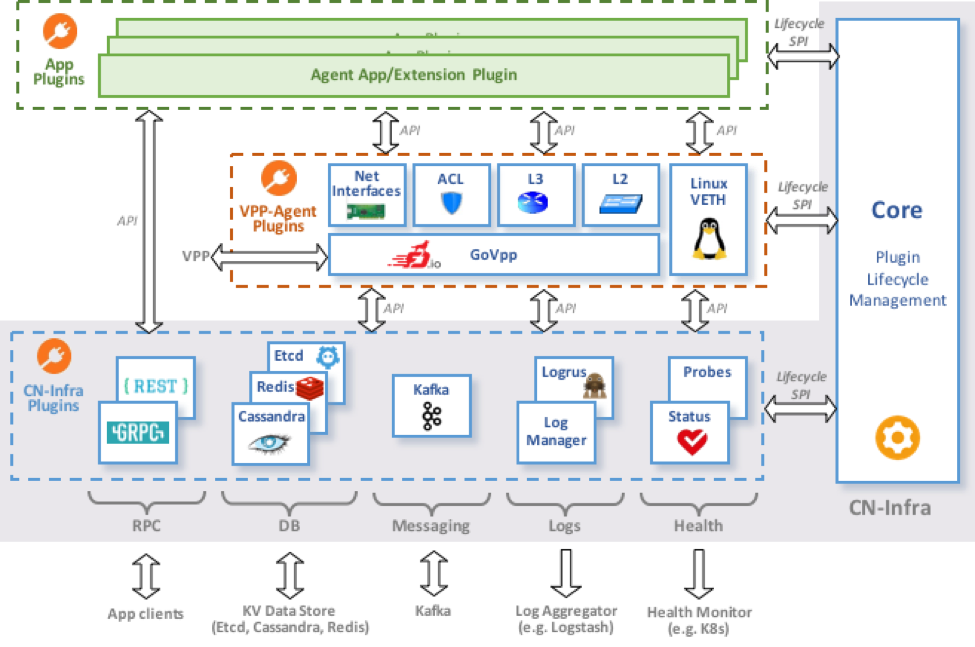
VPP-Agent框架:
项目地址 https://github.com/ligato/vpp-agent
支持的CPU和OS
Architectures
X86/64
ARM-AArch64
Operating Systems:
Debian
Ubuntu
CentOS
OpenSUSE
VPP的功能

VPP网络性能
多核基准性能例子 (UCS-C240 M3, 3.5gHz,所有内存通道转发ipv4):
1 core: 9 MPPS in+out
2 cores: 13.4 MPPS in+out
4 cores: 20.0 MPPS in+out
VPP+DPDK vs OVS+DPDK
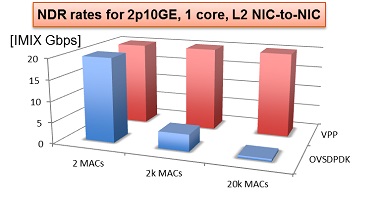
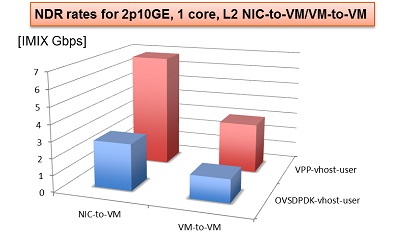
下图是在Haswell x86 架构的E5-2698v3 2x16C 2.3GHz上测试,图中显示了12口10GE,16核,ipv4转发:
VPP功能扩展
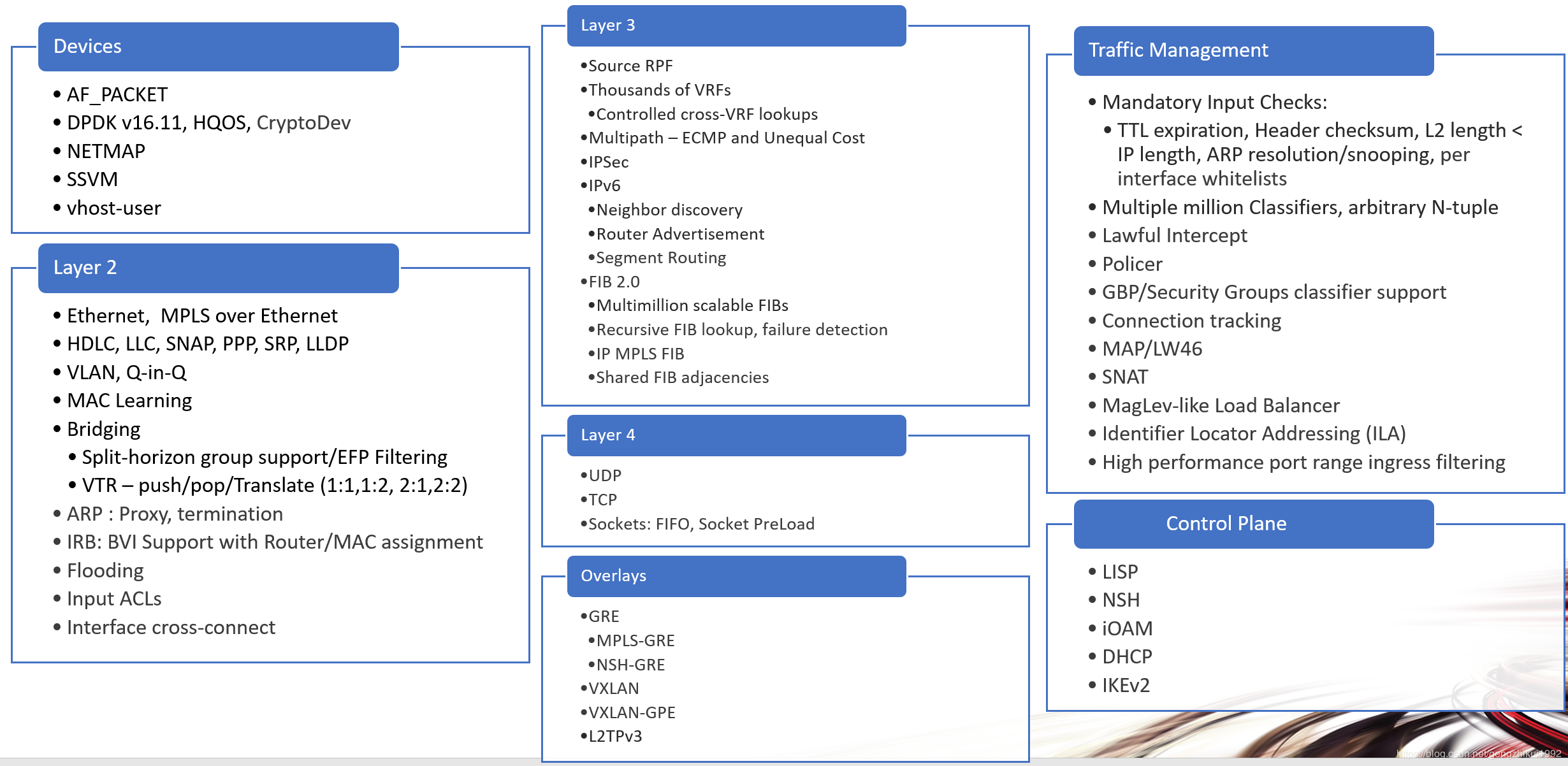
结点操作
VPP平台是通过graphnode串联起来处理数据包,类似于freebsd的netgraph。
通过插件的形式引入新的graph node或者重新排列数据包的gpragh node。将插件添加到插件目录中,运行程序的时候就会自动加载插件。另外插件也可以根据硬件情况通过某个node直接连接硬件进行加速。
通过创建插件,可以任意扩展如下功能:
自定义新的图结点
重新排列图结点
添加底层API
添加插件如下图所示:
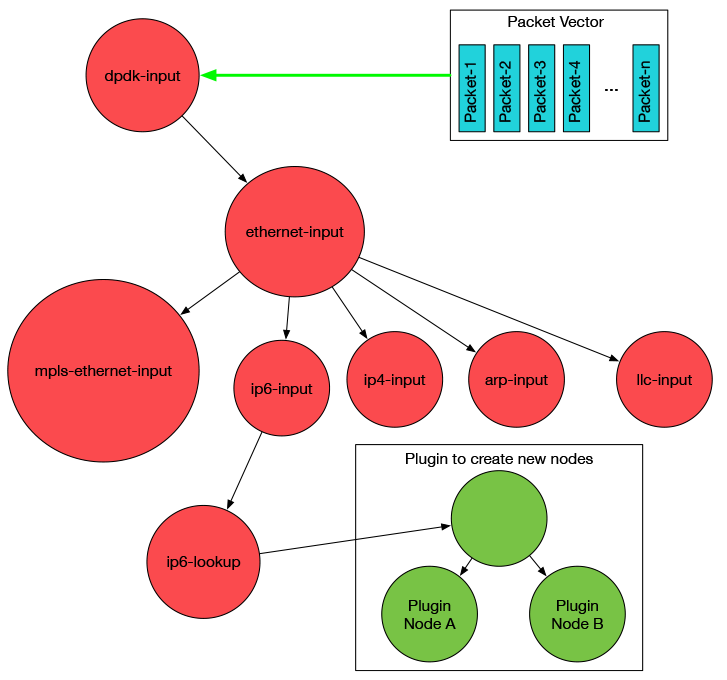
VPP二次开发
VPP源码获取
git clone https://git.fd.io/vpp -b master
代码目录结构
| 目录名称 | 描述说明 |
|---|---|
| build-data | Build metadata |
| build-root | Build output directory |
| doxygen | Documentation generator configuration |
| dpdk | DPDK patches and build infrastructure |
| g2 | Event log visualization tool |
| perftool | Performance tool |
| plugins | VPP bundled plugins directory |
| svm | Shared virtual memory allocation library |
| test | Unit tests |
| vlib | VPP application library source |
| vlib-api | VPP API library source |
| vnet | VPP networking source |
| vpp | VPP application source |
| vpp-api | VPP application API source |
| vppapigen | VPP API generator source |
| vpp-api-test | VPP API test program source |
| vppinfra | VPP core library source |
VPP代码架构
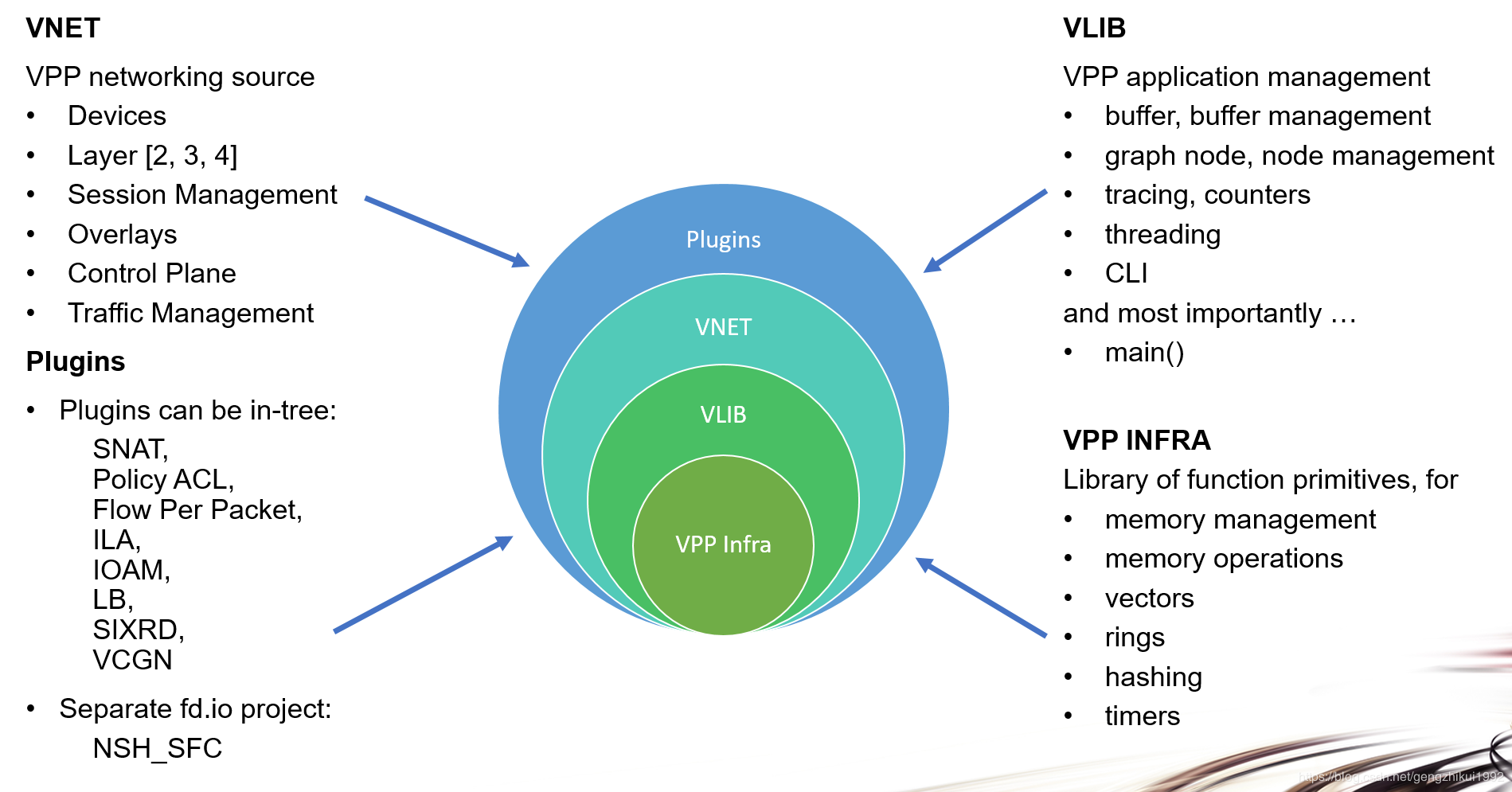
Plugins:主要为实现一些功能,在程序启动的时候加载,一般情况下会在插件中加入一些node节点去实现相关功能
Vnet:提供网络资源能力:比如设备,L2,L3,L4功能,session管理,控制管理,流量管理等
VLIB:主要提供基本的应用管理库:buffer管理,graph node管理,线程,CLI,trace等
VPP Infra:提供一些基本的通用的功能函数库:包括内存管理,向量操作,hash, timer等
VPP安装
源码安装
使用git将VPP源码克隆下来(没有git可使用 yum install git -y 安装)
[root@localhost ~]# mkdir source [root@localhost ~]# cd source [root@localhost source]# git clone https://git.fd.io/vpp -b master安装依赖环境,进入VPP目录下执行:
[root@localhost source]# cd vpp [root@localhost vpp]# yum install -y epel-release python-pip net-tools [root@localhost vpp]# make install-dep安装dpdk,执行第4步代码编译时,会自动下载dpdk并一起编译(可忽略)
[root@localhost vpp]# make dpdk-install-dev进行代码编译(make distclean 可以清除编译生成文件 )
[root@localhost vpp]# make build制作rpm包
[root@localhost vpp]# make pkg-rpm安装VPP
[root@localhost vpp]# cd build-root/ [root@localhost build-root]# rpm -i vpp*.rpm启动VPP(并设置开机启动)
[root@localhost ~]# systemctl enable vpp [root@localhost ~]# systemctl start vpp [root@localhost ~]# systemctl status vpp测试安装是否成功
[root@localhost ~]# vppctl
使用yum安装
安装说明:
vpp 描述:Vector 数据包处理--可执行文件。该软件包提供VPP可执行文件:vpp,vpp_api_test,vpp_json_test
1.vpp: Vector 数据包引擎
2.vpp_api_test: Vector数据包引擎API测试工具
3.vpp_json_test: Vector数据包引擎JSON测试工具
vpp-lib 描述:Vector数据包处理 - 运行时库。该软件包包含VPP共享库,包括:
1.vppinfra:基础库支持vector, hashes, bitmaps, pools, and string formatting
2.svm:vm库
3.vlib:vector处理库
4.vlib-api: binary API库
5.vnet :network stack库
vpp-plugins 描述:Vector数据包处理 - 插件模块,包含以下插件:
1.acl 2.acl 3.dpdk 4.flowprobe 5.gtpu
6.ixge 7.kubeproxy 8.l2e 9.lb 10.memif
11.nat 12.pppoe 13.sixrd 14.stn
vpp-dbg 描述:Vector包处理--debug调试
vpp-dev 描述:Vector数据包处理 - 开发支持。该软件包包含VPP库的开发支持文件
vpp-api-java 描述:JAVA API
vpp-api-python 描述:Python API
vpp-api-lua 描述:Lua API
添加yum源文件
[root@localhost ~]# touch /etc/yum.repos.d/vpp.repo [root@localhost ~]# vi /etc/yum.repos.d/vpp.repo
写入以下内容
[fdio-stable-1801]
name=fd.io stable/1801 branch latest merge
baseurl=https://nexus.fd.io/content/repositories/fd.io.centos7/
enabled=1
gpgcheck=0
更新源缓存
[root@localhost ~]# yum clean all [root@localhost ~]# yum makecache [root@localhost ~]# yum install -y epel-release python-pip安装vpp
[root@localhost ~]# yum install vpp -y可选安装(vpp-plugins包含将dpdk驱动程序用于硬件接口所需的dpdk-plugin)
根据需要可选安装:vpp-devel vpp-api-python vpp-api-lua vpp-api-java [root@localhost ~]# yum install -y vpp-plugins
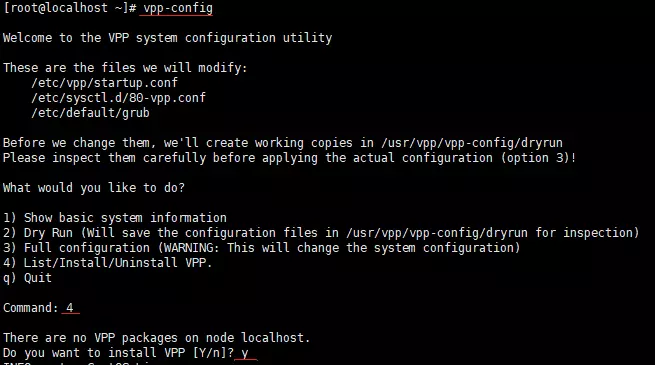
使用vpp-config安装
安装pip
[root@localhost ~]# yum install -y epel-release python-pip安装vpp-config
[root@localhost ~]# pip install vpp-config安装vpp
[root@localhost ~]# vpp-config
vppctl和vat(vpp-api-test)
安装完vpp后可以使用vppctl命令行和vat api测试工具
VPP配置
配置文件:startup.cfg(/etc/vpp/startup.cfg)
/*****************************************************************************/
unix {
Interactive //将CLI命令加入到输入输出,提供调试
log /tmp/vpp.log //日志
full-coredump //请求Linux内核转储所有内存映射地址区域
cli-listen 127.0.0.1:5002 //绑定CLI监听TCP端口5002
}
api-trace {
on //程序崩溃时可以追踪
}
cpu {
//works <n> //创建n个线程
//skip_cores <n> //对于worker线程来说跳过前n个核
main-core 0 //将主线程分配给第0个核
corelist-workers 1-3 //将worker线程放到核1 2 3上
}
dpdk {
dev default {
num-rx-desc 4096
num-tx-desc 4096
}
dev 0000:04:00.0 {num-rx-queues 1} //将网卡与网卡驱动绑定
dev 0000:04:00.1 {num-rx-queues 1}
dev 0000:05:00.0
dev 0000:05:00.1
num-mbufs 128000 //IO缓冲区数量
socket-mem 2048 //vpp感知NUMA,在NUMA0上分配2G内存
}
plugin_path{
/usr/lib/vpp_plugins
//插件路径
}
/*****************************************************************************/
VPP参考
https://blog.csdn.net/sjin_1314/article/details/101098803
UPF
N4接口
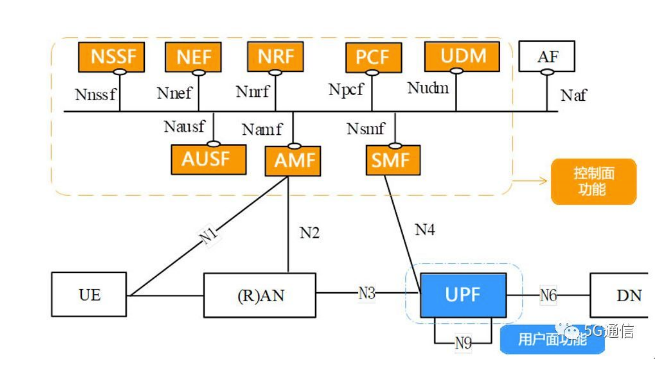
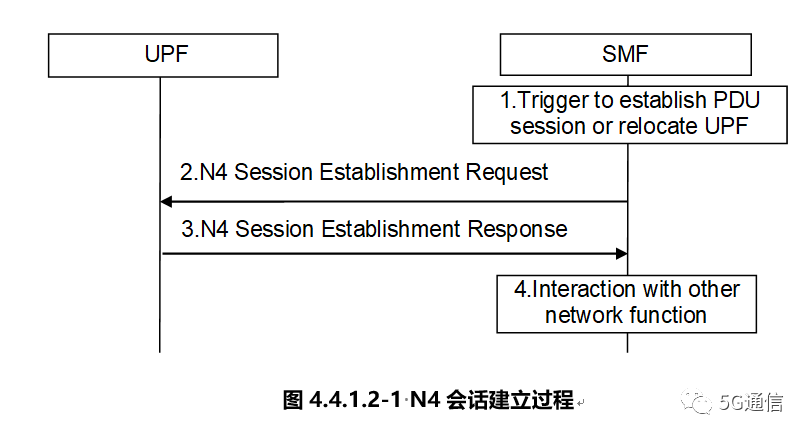
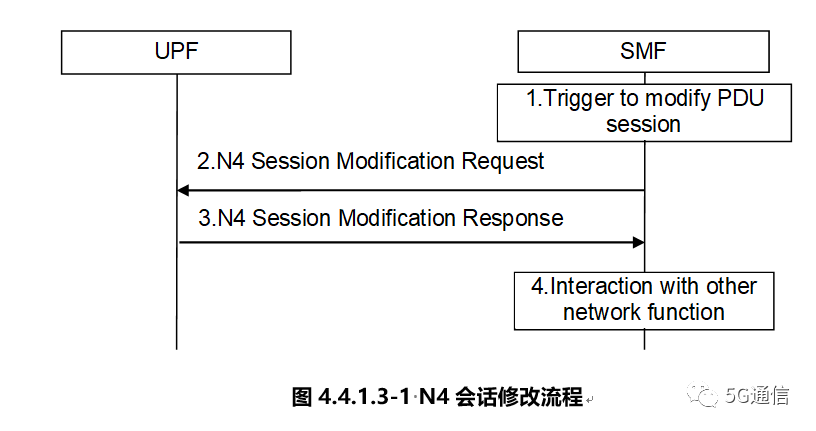
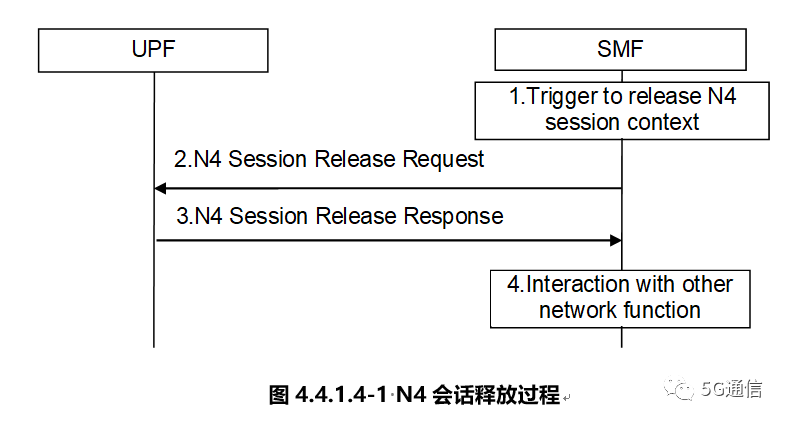
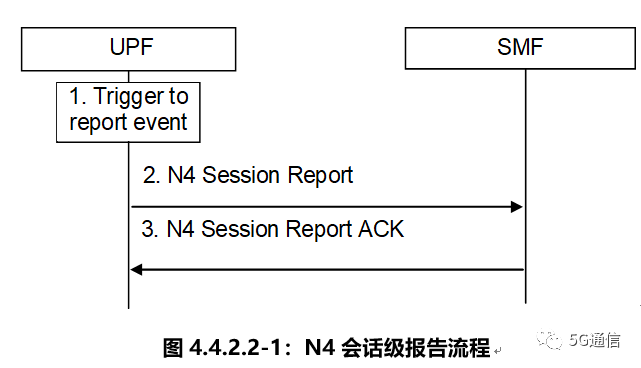
UPF需要实现的主要功能
- 系统内外移动性锚点
- 与数据网络互连的外部PDU会话点
- 分组路由和转发
- 数据包检查和用户平面部分的策略规则实施
- 上行链路分类器,支持将流量路由到数据网络
- 分支点以支持多宿主PDU会话
- 用户平面的QoS处理,例如,包过滤,门控,UL / DL速率执行
- 上行链路流量验证(SDF到QoS流量映射)
- 下行链路分组缓冲和下行链路数据通知触发